

Reconstructing and Analyzing the Evolution of Stack Overflow Posts
TL;DR: Like other software artifacts, questions and answers on Stack Overflow evolve over time, for example when bugs in code snippets are fixed or text surrounding a code snippet is edited for clarity. To be able to analyze how Stack Overflow posts evolves, we built SOTorrent, an open dataset based on the official Stack Overflow data dump. SOTorrent provides access to the version history of Stack Overflow content at the level of whole posts and individual text or code blocks. It connects Stack Overflow posts to other platforms by aggregating URLs from text blocks and by collecting references from GitHub files to Stack Overflow posts. The dataset is available on Zenodo and Google BigQuery.
Information about the most recent database layout and dataset version can be found on the SOTorrent project page.
Motivation
Similar to other software artifacts such as source code files and documentation, text and code snippets on Stack Overflow evolve over time, for example when the community fixes bugs in snippets, clarifies questions and answers, or updates documentation to match new API versions. Since the inception of Stack Overflow in 2008, a total of 13.9 million SO posts have been edited after their creation—19,708 of them more than ten times (as of December 1, 2017). While many Stack Overflow posts contain code, the evolution of code snippets on Stack Overflow differs from the evolution of entire software projects: Most snippets are relatively short (on average 12 lines) and many of them cannot compile without modification. Moreover, Stack Overflow does not provide a version control or bug tracking system for post content, forcing users to rely on the commenting function or additional answers to voice concerns about a post.
The offical Stack Overflow data dump contains different versions of entire posts, but does not contain information on a more fine-grained level. In particular, it is not trivial to extract different versions of the same code snippet from the post history to analyze its evolution. To be able to analyze the evolution of Stack Overflow posts in detail, we built the open dataset SOTorrent.
The SOTorrent Dataset
SOTorrent is based on data from the official Stack Overflow data dump and the Google BigQuery GitHub dataset (information about included projects can be found here). It provides access to the version history of Stack Overflow content at the level of whole posts and individual post blocks. A post block can either be a text or a code block, depending on how the author formatted the content (see example below). Beside providing access to the version history, the dataset links Stack Overflow posts to external resources in two ways: (1) by extracting linked URLs from text blocks of Stack Overflow posts and (2) by providing a table with links to SO posts found in the source code of GitHub projects.
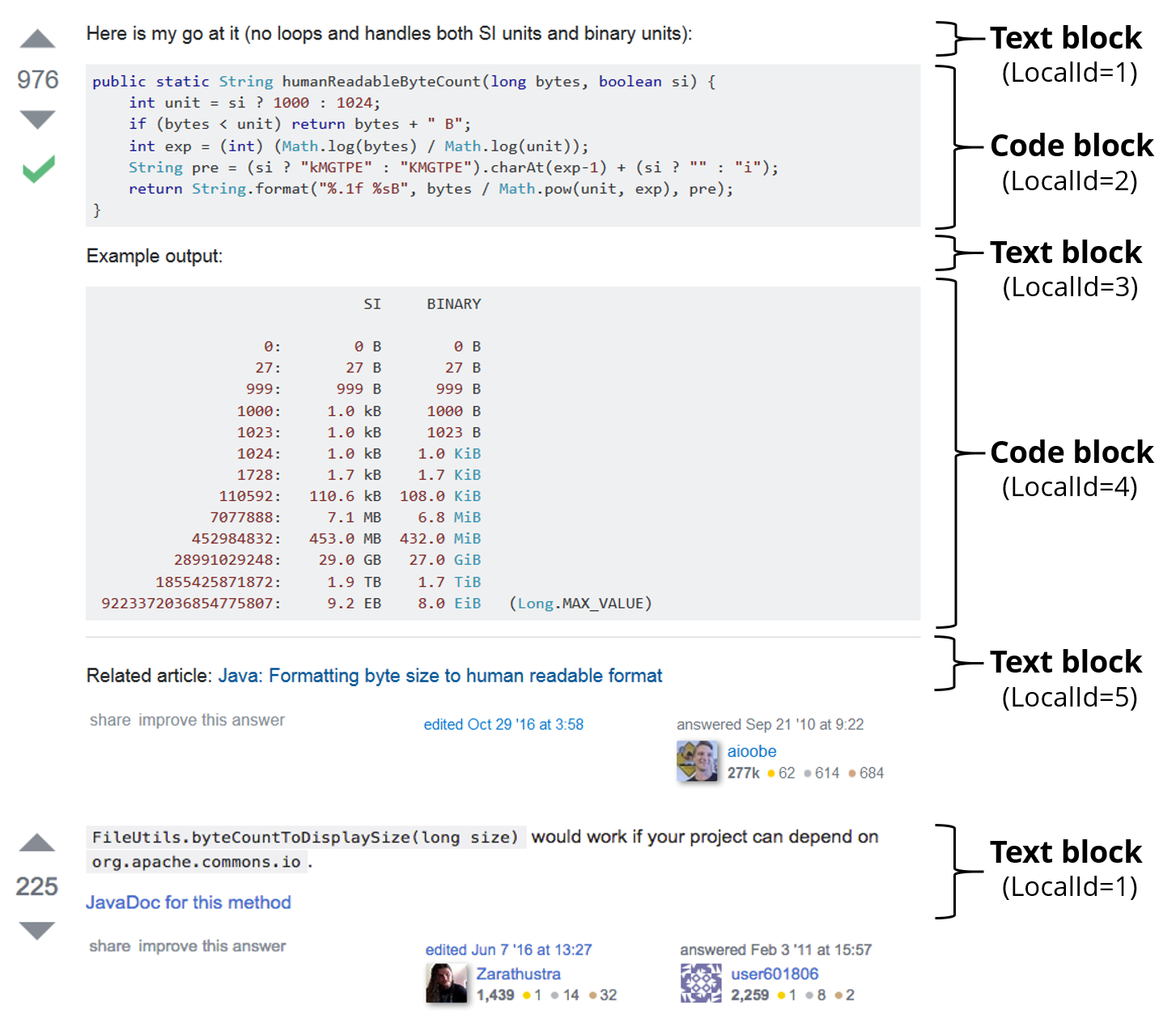
Source: How to convert byte size into human readable format in java?
Data sample
To illustrate how one can use SOTorrent to analyze the evolution of Stack Overflow posts, we investigate one of the most popular Java answers on Stack Overflow, which is aioobe’s answer to the question How to convert byte size into human readable format in java?. The following SQL queries are tested on a MySQL 5.7 database with SOTorrent 2018-02-16. Please note that the SOTorrent-specific IDs (e.g., PostVersionId or PostBlockVersionId) may differ between different SOTorrent versions, but the IDs from the official data dump (e.g., PostId or PostHistoryId) are stable. See our MSR mining challenge proposal for queries that only rely on stable IDs. The BigQuery versions of the below queries can be found here. We start by retrieving all post block versions of this answer using the post id:
SELECT *
FROM PostBlockVersion
WHERE PostId=3758880
ORDER BY PostHistoryId ASC, LocalId ASC;
The following figure shows the result of the above query for the two most recent post versions (1):
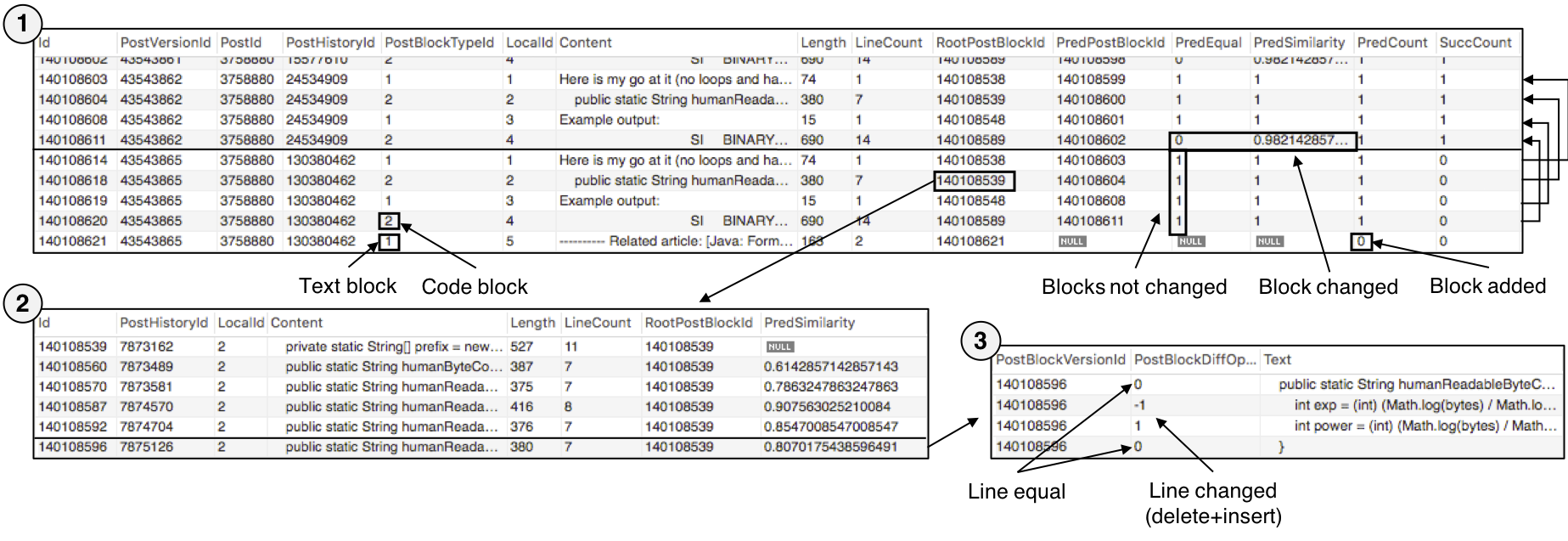
We define post block lifespans as chains of connected post block versions that are predecessors of each other. Those lifespans can be easily retrieved from the database, because each post block version has a RootPostBlockId, which is the id of the first post block version in the chain. In the query used to create part (2) of the figure, we only selected versions where the content of the code block actually changed (not all post blocks are changed in all post versions):
SELECT Id, PostHistoryId, LocalId, Content, Length, LineCount, RootPostBlockId, PredSimilarity
FROM PostBlockVersion
# this ID changes between dataset versions
WHERE RootPostBlockId=140108539
AND (PredEqual IS NULL OR PredEqual = 0)
ORDER BY PostHistoryId ASC;
To see which lines were changed in a particular version, we can utilize table PostBlockDiff. The result of the following query is shown in part (3) of the figure:
SELECT PostBlockVersionId, PostBlockDiffOperationId, Text
FROM PostBlockDiff
# this ID changes between dataset versions
WHERE PostBlockVersionId=140108596;
We can also use SOTorrent to retrieve files on GitHub that reference this particular answer:
SELECT RepoName, Branch, Path, FileExt, Copies, PostId, SOUrl, GHUrl
FROM PostReferenceGH
WHERE PostId=3758880;
Result:

To retrieve links from all text block versions of the post, we can use table PostVersionUrl:
SELECT *
FROM PostVersionUrl
WHERE PostId=3758880;
In this case, only one post block version contained a link, which referred to a blog post with the same snippet:

Availability
SOTorrent is available as a database dump (including import scripts) on Zenodo and as a public Google BigQuery dataset. The BigQuery dataset does not contain the tables from the official Stack Overflow data dump, because they are already available as a separate public dataset. Starting with SOTorrent release 2018-03-28, the tables from the official Stack Overflow data dump are included.
Database schema
SOTorrent contains all tables from the official Stack Overflow data dump. To analyze how individual text or code blocks evolve, we needed to extract individual blocks from the Markdown-formatted content in table PostHistory of that data dump. One version of a post corresponds to one row in the table. However, the table does not only document changes to the content of a post, but also changes to metadata such as tags or title. Thus, we had to filter and process the available data. First, we selected edits that changed the content of a Stack Overflow post, identified by their PostHistoryTypeId (2, 5, 8, see documentation). We linked each filtered version to its predecessor and successor and stored it in table PostVersion.
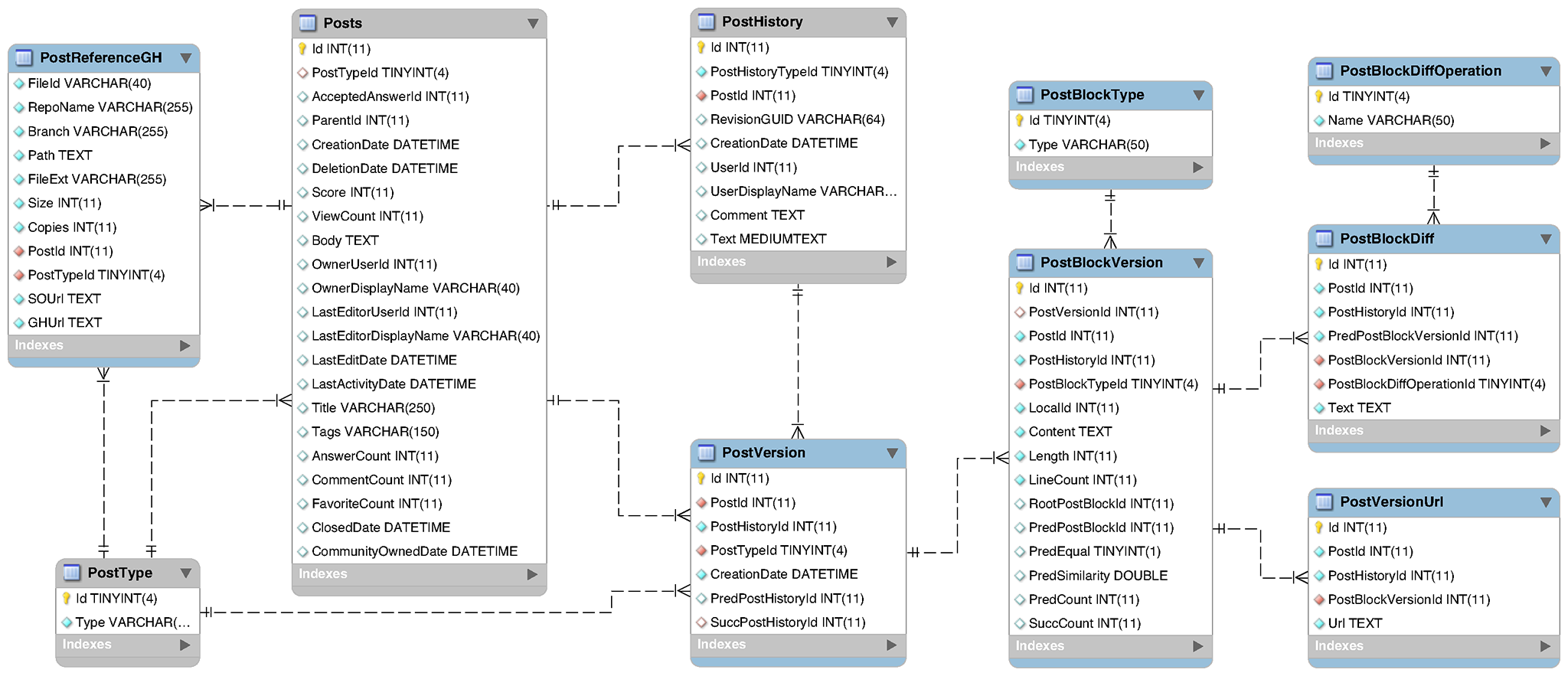
We split the Markdown-formatted content of each version into text and code blocks and extracted the URLs from all text blocks using a regular expression (table PostVersionUrl). To reconstruct the version history of individual post blocks (table PostBlockVersion), we established a linear predecessor relationship between the post block versions using a string similarity metric that we selected after a thorough evaluation. For each post block version, we computed the line-based difference to its predecessor, which is available in table PostBlockDiff.
One row in table PostReferenceGH represents one link from a file in a public GitHub repository to a post on Stack Overflow.
To extract those references, we utilized the Google BigQuery GitHub dataset and applied a regular expression matching Stack Overflow URLs to each line of each non-binary file in the dataset.
Because there are different ways of referring to questions and answers on SO, that is using full URLs or short URLs, we mapped all extracted URLs to their corresponding sharing link (ending with /q/<id> for questions and /a/<id> for answers) and saved that link together with information about the file and the repository in which the link was found in the database.
We ignored other links referring to, for example, users or tags on Stack Overflow.
More Information
This blog post skips many details about the extraction of the version history and the evaluation of different string similarity metrics. A more detailed description including first insights into the evolution of Stack Overflow posts can be found in the corresponding research paper. The software used for building and analyzing SOTorrent is available on GitHub.
Acknowledgements
I would like to thank my co-authors Lorik Dumani, Christoph Treude, and Stephan Diehl. Thanks also to Tobias Zeimetz for creating the post history ground truth, to Florian Reitz for his help with database-related issues, and to Felipe Hoffa for his support.