GenAI vs. Calculators?
Calculator introduction in schools was controversial. Analogy for GenAI?


Hi, my name is Sebastian Baltes,
I am a Professor of Software Engineering at Heidelberg University, Germany, where I lead the Software Engineering Group. I am also an Adjunct Professor at the University of Adelaide, Australia, where I previously worked as a Continuing Lecturer of Software Engineering. Until September 2025, I was a Professor of Software Engineering at the University of Bayreuth, Germany. Before re-joining academia, I worked in the software industry for 3.5 years, first as a Senior Software Developer at QAware GmbH and then later as a Principal Expert for Empirical Software Engineering at SAP SE. You may also visit my LinkedIn profile.
My research falls into what I call the triangle of empirical software engineering. From the beginning of my career, I have been interested in leveraging empirical research to study phenomena in software engineering practice, with the goal of deriving actionable insights and requirements for better tool support.
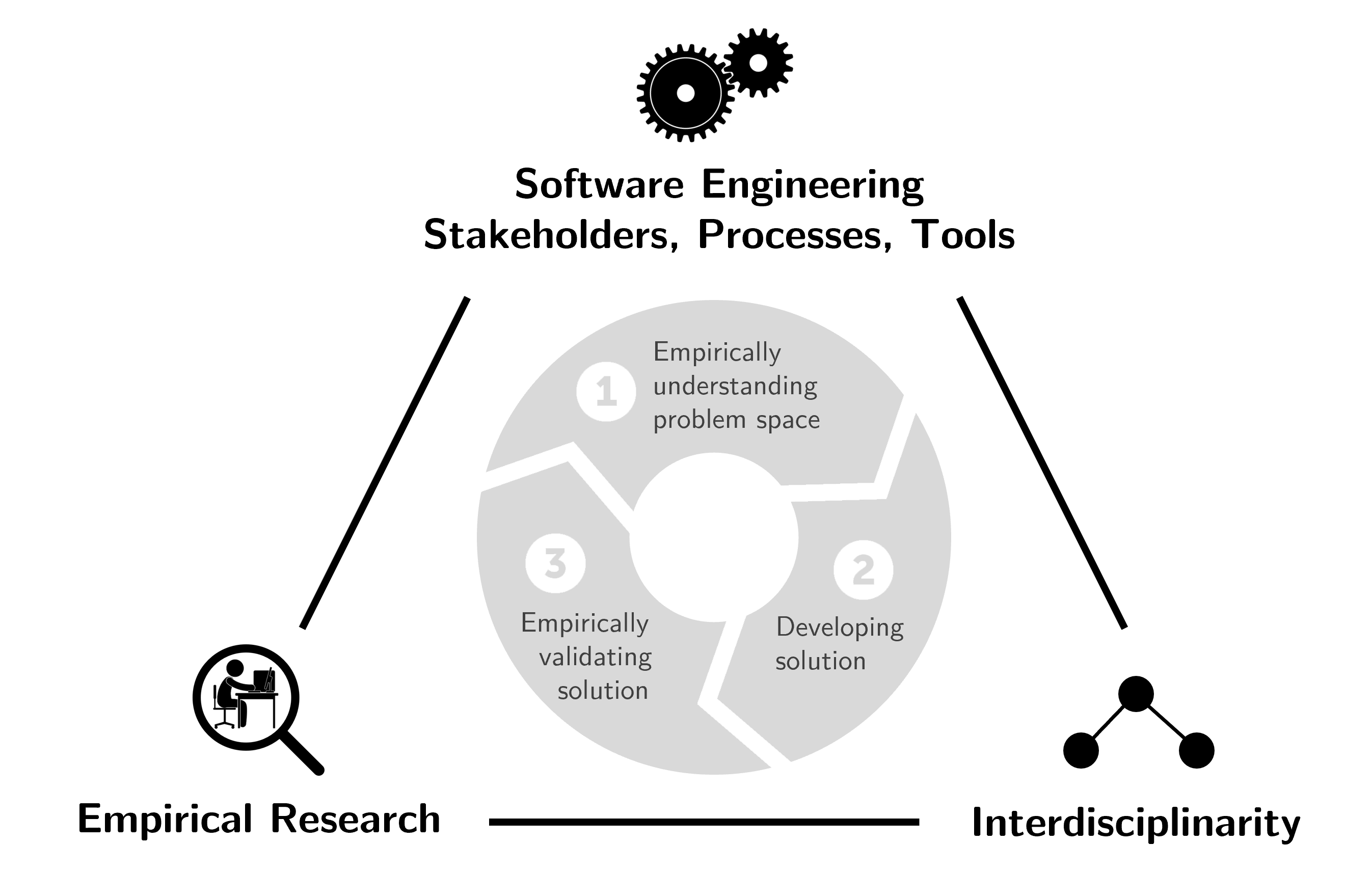
The guiding theme of my research is the idea that thoroughly analyzing and understanding the state-of-practice is an essential first step towards improving how software is being developed. Too often, decisions in software projects are opinion-based rather than data-informed. Most research projects I work on have an interdisciplinary angle, including work with connections to psychology, law, social science, and management. I consider myself a methods pluralist, combining qualitative methods such as interviews and observational studies with large-scale quantitative data mining of open-source projects, industrial datasets, and curated corpora such as SOTorrent, the official MSR 2019 mining challenge dataset that we maintained between 2017 and 2020 [C5], [S7]. I follow open science and open data practices by publishing data, analysis scripts, and paper preprints whenever possible.
I have successfully applied this philosophy in industry as well: As Principal Expert for Empirical Software Engineering at SAP, I regularly utilized empirical methods to identify problems with existing development processes and tools, deriving guidelines and requirements for better tooling. After moving back to academia, I have been continuing this line of work first at the University of Bayreuth and now at Heidelberg University, with a strong focus on academically excellent but practically relevant research. Our ongoing collaboration with SAP on test flakiness exemplifies this approach Our work on timeout-induced flakiness [C10], [C11] directly influenced how SAP HANA handles test timeouts, the latter receiving a Best Paper Award at ESEM 2024, and we recently extended this work to study the flakiness of LLM-generated tests [C15], [C16]. My background as a software engineer in different companies helps me balance the perspectives of researchers, practitioners, and other stakeholders; I actively communicate scientific results back to practice through talks and other communication channels.
You can find more information about my research on the research page.
Consider submitting to the Empirical Software Engineering journal, where I'm a member of the editorial board.
Calculator introduction in schools was controversial. Analogy for GenAI?
Embracing GenAI in software development while resisting the hype
New online survey focusing on role transitions and reorganizations of employees in software development roles
Guidelines for empirical studies in software engineering involving large language models
Updated Google Scholar metrics still list our papers as top two